AI, Work & Governance
Sample Project: Algorithmic Management (Ongoing)
Sample Project: Algorithmic Institutions (Ongoing)
Sample Project: Welfare AI (Ongoing)
How to govern and be governed by AI?
Corporations and government bureaucracies are often likened to machines, with individual workers and bureaucrats being merely cogs. In the future, however, both corporations and governments may become machine-operated in a more literal sense. AI algorithms, powered by ever-growing data, provide opportunities for automating many decisions, from hiring and firing employees to allocating government welfare benefits.
Algorithmic decision making in government and business provides immense opportunities for faster, more economically efficient outcomes. It also has the potential to produce socially desirable outcomes that eliminate human error and bias. At the same time, algorithmic decision-making systems raise the possibility of perpetuating entrenched problems. For example, consider an AI system trained to evaluate resumes for short-listing candidates more rapidly. If this system is trained on biased data, it would simply reproduce such biases, rather than select the best candidates for the job.
Another question that such systems raise is how societies agree on the objective function for which the algorithm optimizes. Economic and social objectives often conflict with one another, and are prioritized in different ways based on one’s beliefs and political ideology. This necessitates a mechanism for identifying such conflicts in values, and for subsequently resolving them to produce acceptable outcomes.
This research area explores the promises and challenges that arise when AI systems are used to govern or manage people, whether in a political realm or a commercial context.
Sample Project: Algorithmic Management (Ongoing)
Previous studies on people’s attitudes toward algorithmic management yield inconsistent findings, and field experiments on crowdsourced marketplaces can overcome their methodological limitations.
Algorithms powered by artificial intelligence (AI) are increasingly involved in the management of organizations, a development that has spurred much research oriented toward efficiency, revenue, and innovation (Kellogg et al., 2020, Algorithms at work: The new contested terrain of control). The use of algorithms in managing workers has also become an important domain for exploring people’s feelings and behaviors where machines gain power over humans (Glikson & Woolley, 2020, Human trust in artificial intelligence: Review of empirical research). The two most common methodological paradigms to collect data on human reactions to algorithmic management are vignette studies and case studies. In vignette studies, participants are presented with hypothetical scenarios in which they are managed by algorithms, and are asked to anticipate how they would feel and behave. Case studies, on the other hand, recruit participants who work in a company that has already deployed algorithmic management, and integrate data from surveys, interviews, text analysis, or observation to gauge how they actually feel and behave in their dealings with algorithmic managers. However, findings from these two sources of data are often inconsistent. Our aims are (1) to summarize inconsistent findings from these two mainstream methods and their respective limitations, and (2) to testify to a potential methodological solution, that is, to conduct field experiments on crowdsourced marketplaces.
First, we list previous empirical evidence suggesting that participants in case studies often display more positive attitudes toward algorithmic managers than participants in vignette studies. We then reason that the two methods reveal conflicting results due to their respective limitations as summarized in Figure 1.

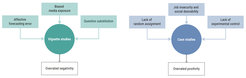
Figure 1. Limitations of previous studies on the psychology of algorithmic management.
Subsequently, we conducted one proof-of-concept experiment (N = 504) to validate field experiments on crowdsourced marketplaces as a method that can overcome both the limitations of vignette studies and the limitations of case studies, using their original function as online labor markets (Horton et al., 2011, The online laboratory: Conducting experiments in a real labor market). As summarized in Figure 2, we found that what workers said and did in our field experiment stood somewhere in between the findings reported in vignette studies and the findings reported in case studies. In contrast to what participants pessimistically predicted in vignette studies, workers in our field experiment did not show lower commitment under algorithmic management, and did not feel algorithmic managers to be less fair than human managers. In contrast to what employees optimistically reported in case studies, workers in our field experiment did not show higher performance or motivation under algorithmic managers.
.")
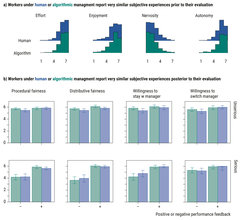
Figure 2. Results of Mturk field experiment on algorithmic management (N = 504).
We suggest that field experiments in crowdsourced marketplaces have the potential to help simulate the future of work and facilitate timely research on management technologies, to consolidate tentative findings from vignette and case studies, to make more accurate predictions about workers’ feelings and behaviors under algorithmic management, and to indicate directions where human-centered work designs should be experimented with and implemented. In the near future, we also aim to test the psychology of AI management in higher-fidelity environments (e.g., in Minecraft).
Sample Project: Algorithmic Institutions (Ongoing)
The project investigates whether humans would voluntarily opt into a social contract with an algorithmic governing system that has the superior ability, compared to humans, to facilitate human cooperation through efficient sanctioning methods.
Institutions aim to establish and stabilize cooperation in groups, including detection and punishment of misconduct. When a human leader has the power to punish, such regimes successfully establish cooperation, and are preferred to institutions without sanctioning (Gürerk, Irlenbusch & Rockenbach, 2006, The competitive advantage of sanctioning institutions; Fehr and Gächter, 2000, Cooperation and punishment in public goods experiments). Yet, the role of algorithm-led institutions as an attractive, unbiased alternative to human-managed institutions is unexplored. Here, we examine two fundamental questions:
- Can an algorithmic institution with adaptive punishment promote cooperation in groups more efficiently?
- Would people voluntarily opt into a social contract that grants an algorithmic institution monopoly on punishment?
We explore this in the context of a public goods game, in which participants in a group can decide to use their own tokens to fill up a common pool that is later distributed across all group members. This game induces a social dilemma, as participants benefit from the contribution of other participants irrespective of their own contribution. In our version of the experiment, a manager can punish participants based on their contributions. In our study, we first let participants in an online experiment interact in a public goods game with either a human manager or an algorithmic manager. Thereafter, we let participants choose several institutions with either a human or an algorithmic monopoly on power.
Our aim is to extend previous work by Gürerk et al. (2006) by:
- exploring whether people voluntarily opt into a regime in which an algorithm has the monopoly of power to achieve cooperation and total welfare
- exploring whether such an algorithmic institution has a competitive advantage over a human-run institution
To train the algorithmic manager, we follow the training protocol of Koster et. al (2022, Human-centred mechanism design with Democratic AI) by first training models representing human behavior on pilot data and then using these “artificial participants” to optimize a reinforcement learning-based model. In two large-scale pilot studies, we collected human contributions in a social goods game with a central sanctioning institution, i.e., the manager. Based on the collected data, we trained “artificial human contributors,” neural network-based models predicting human contributions contingent on received punishments. Second, we trained an “artificial human manager,” a similar model predicting punishments of a human manager. Finally, we used reinforcement learning to find a policy for an “optimal manager” who maximizes the common good when interacting with the trained “artificial human contributors.”
Figure 3 depicts the expected contributions, punishments, and common good based on simulations with the different models. In controlled experiments, we are now investigating the actual performance of the algorithmic manager as well as the self-selection of participants into different institutions.
 a pilot study in which human participants were managed by another humans; (red) a pilot study in which human participants were managed by diversely parametrized rules; (blue) a simulation of artificial humans managed by an artificial human manager reproducing human behavior; and (orange) a simulation of artificial humans being managed by an algorithm trained through reinforcement learning to optimize the common good.")

Sample Project: Welfare AI (Ongoing)
In evaluating the accuracy–efficiency trade-off of welfare AI, opinions of the general population are heterogeneous, and, more importantly, the perspective of vulnerable groups cannot be easily understood and should be prioritized.
Human decisions are increasingly delegated to artificial intelligence (AI), and such a transition often requires resolving ethical trade-offs. One case in point can be the accuracy–efficiency trade-off for welfare AI. As soon as AI makes automated decisions for social welfare distributions, people can profit from faster decisions and more efficient public services. However, even though the AI systems can improve by trial and error over time, in this process people may still suffer from the mistakes of premature AI systems. To inform their decision making and improve public acceptability of the delegation to AI systems, policy-makers may want to collect citizen preferences.
One central question, then, is to determine whose preferences should be taken into account. One golden rule may be to solicit opinions from a representative sample of the general population and provide average results. However, this may not be the optimal solution for all AI products alike, and the deployment of welfare AI may instead need to de-emphasize the preferences of the general population and seek opinions from people who are most impacted by welfare decisions or likely to become welfare claimants (e.g., older, low-income, or unemployed people; Shah et al., 2012, Some consequences of having too little).
If people indeed have heterogeneous opinions on the ethical trade-offs of welfare AI (Bryan et al., 2021, Behavioural science is unlikely to change the world without a heterogeneity revolution), it is thus important to have other people’s buy-in, in order to build welfare AI programs that are not tailored to their own preferences but to those of vulnerable groups. People often infer others’ preferences with a bias toward their own experience, particularly when they possess more resources and generally experience less precarious circumstances in their everyday life (Haselton et al., 2006, The paranoid optimist: An integrative evolutionary model of cognitive biases). Put differently, non-vulnerable groups may have a harder time taking the perspective of vulnerable groups into account to accurately estimate vulnerable people’s preferences for welfare AI (versus vice versa).
We therefore aim to quantify ethical standards regarding their salient accuracy–efficiency trade-offs, to discern heterogeneous groups (if applicable) and their characteristics, and to examine whether people are able to take into account a different perspective and accurately evaluate other people’s preferences. We conducted two experiments, on a representative sample in the United States and on a balanced sample of welfare claimants versus non-claimants in the United Kingdom respectively (total N = 2449).
As summarized in Figure 4, we found that people indeed traded accuracy for efficiency in their preferences for delegating welfare decisions to AI. When evaluating such ethical trade-offs, however, opinions from the general population were largely heterogeneous. While the people who had very pessimistic attitudes towards welfare AI, regardless of its performance, constitute only a minority group—comprising older people with a lower income and actual welfare claimants—their voices should not be ignored because it is this group that is often in a vulnerable position and their respective perspectives cannot be easily understood by other non-vulnerable groups.


Figure 4. Key findings of the two studies on people’s preferences for welfare AI.